
◀背景▶
对于一套分布式部署的 IM 系统,要求每条消息的 ID 要保证在集群中全局唯一且按生成时间有序排列。如何快速高效的生成消息数据的唯一 ID ,是影响系统吞吐量的关键因素。那么,融云是如何做到生成全局唯一消息 ID 的呢?
首先需要明确下 ID 生成的核心需求:
1. 全局唯一
2. 有序
◀设计▶
融云消息数据的唯一 ID 长度采用 80 Bit 。每 5 个 Bit ,进行一次 32 进制编码,转换为一个字符,字符取值范围是,( 2 ~ 9 ) 和 ( A ~ B ),其中,已经去掉容易造成肉眼混淆的,数字 0 和 1 ,及字母 O 和 I 。这样,80 Bit 可以转换为 16 个字符,再加上 3 个分隔符( - ),将 16 个字符分为 4 组,最终得到一个 19 字符的唯一 ID 。 这样设计,即可以保证生成的 ID 是有序的,也能方便阅读。
如上图所示,80 Bit 被分为 4 段:
1. 第一段 42 Bit ,用于存放时间戳,最长可表示到 2109 年,足够开发者当前使用了。时间戳数据放在高位,可以保证生成的唯一 ID 是按时间有序的,这个是消息 ID 必须要满足的条件。
2. 第二段 12 Bit ,用于存放自旋转 ID 。我们知道,时间戳的精度是到毫秒的,对于一套亿级 IM 系统来说,同一毫秒内产生多条消息太正常不过了,这个自旋 ID 就是在给落到同一毫秒内的消息进行自增编号。12 Bit 则意味着,同一毫秒内,单台主机中最多可以标识 4096( 2 的 12 次方)条消息。
3. 第三段 4 Bit ,用于标识会话类型。4 Bit ,最多可以标识 16 中会话,足够涵盖单聊、群聊、系统消息、聊天室、客服及公众号等常用会话类型。
4. 第四段 22 Bit ,会话 ID 。如群聊中的群 ID ,聊天室中的聊天室 ID 等。与第三段会话类型组合在一起,可以唯一标识一个会话。其他的一些 ID 生成算法,会预留两段,分别用来标识数据中心编号和主机编号(如 SnowFlake 算法),我们并没有这样做,而是将这两段用来标识会话。这样,ID 生成可以直接融入到业务服务中,且不必关心服务所在的主机,做到无状态扩缩容。
◀实现过程▶
消息 ID 共占 80 Bit ,计算时我们分为两部分,高 64 Bit (记为 highBits )和低 16 Bit (记为 lowBits )。
1. 获取当前系统的时间戳,并赋值给消息 ID 的高 64 Bit ;

2. 获取一个自旋 ID , highBits 左移 12 位,并将自旋 ID 拼接到低 12 位中;
其中,自旋 ID 是一个从 0 到 4095 范围内,顺序递增的数,生成规则如下:
3. 上步的 highBits 左移 4 位,将会话类型拼接到低 4 位;
4. 取会话 ID 哈希值的低 22 位,记为 sessionIdInt ;
5. highBits 左移 6 位,并将 sessionIdInt 的高 6 位拼接到 highBits 的低 6 位中;
6. 取会话 ID 的低 16 位作为 lowBits ;
7. highBits 与 lowBits 拼接,得到 80 Bit 的消息 ID 。对其进行 32 进制编码,即可得到唯一消息 ID 。编码规则如下:从左至右,每 5 个 Bit 转换为一个整数,以这个整数作为下标,即可在下表中找到对应的字符。
总结:
这种 ID 生成的方式,需要注意保证自旋 ID 的生成是线程安全的。避免在并发情况下,生成出同样的 ID 。另外,此 ID 生成算法,强烈依赖系统时间,如果系统时间被改小,也可能造成 ID 生成重复。
 艾普奖|庄子峰荣获2 ITALIAN MODERN 设计,重塑生活的一种方式。 以独特、…
艾普奖|庄子峰荣获2 ITALIAN MODERN 设计,重塑生活的一种方式。 以独特、…
 潜心打磨缔造唯一 劳斯莱 Bespoke高级定制的幻影长轴距车型——幻影“…
潜心打磨缔造唯一 劳斯莱 Bespoke高级定制的幻影长轴距车型——幻影“…
 三星Neo QLED 8K电视,和这 在2021年国际消费类电子产品展览会(CES)上,三星在“First Look”…
三星Neo QLED 8K电视,和这 在2021年国际消费类电子产品展览会(CES)上,三星在“First Look”…  三星电视:做时代的引领者 家电圈近期最值得期待的看点非三星电视莫属,除了一系列科技大片即视感的VLO…
三星电视:做时代的引领者 家电圈近期最值得期待的看点非三星电视莫属,除了一系列科技大片即视感的VLO…  影创科技集团董事长孙立荣 2019年度商界青年领军者获奖人——爱库存联合创始人冷静女士为孙立颁奖....…
影创科技集团董事长孙立荣 2019年度商界青年领军者获奖人——爱库存联合创始人冷静女士为孙立颁奖....…  共绘XR文旅蓝图,影创科技 此次战略合作签约仪式意味着双方建立起长期战略合作伙伴关系,影创科技与江西旅游…
共绘XR文旅蓝图,影创科技 此次战略合作签约仪式意味着双方建立起长期战略合作伙伴关系,影创科技与江西旅游…  南昌市工商联党组书记熊冬 调研组一行在体验 5G+MR 全息智慧教室后对其丰富、直观、立体的教学形式表示赞许…
南昌市工商联党组书记熊冬 调研组一行在体验 5G+MR 全息智慧教室后对其丰富、直观、立体的教学形式表示赞许…  《少年三国志2》共筑军团 今天要给少年们介绍的就是中的军团玩法,快点跟紧队伍,不要走神…
《少年三国志2》共筑军团 今天要给少年们介绍的就是中的军团玩法,快点跟紧队伍,不要走神…
 分享至新浪微
分享至新浪微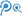 转播到腾讯微博
转播到腾讯微博













